[CICD] Grafana, Prometeus, Promtail, Loki 모니터링 해보기
모니터링
모니터링은 다양한 이유로 필요하다. 운영상에 에러 발생시 빠른 확인, 그 에러 원인에 대한 빠른 분석, 기존 시스템 상태 분석을 통한 개선점 파악, 사용자 행동 패턴 분석 등 다양한 시스템에 대해 빠른 조치나 개선을 할 수 있게 해준다.
모니터링 아키텍처 종류
모니터링을 위해 고려되는 아키텍처에는 3가지 정도가 있다.
CloudWatch
CloudWatch 모니터링 시스템은 AWS 에서 제공하고 대시보드, 알림, 통합 로그 등 다양한 기능이 있지만 비용이 청구되므로 사용하지 않았다.
ELK
Elasticsearch, Logstash, Kibana 로 구성한 모니터링 시스템이다. 강력한 로깅 관리 기능을 제공하고 대용량 데이터 처리에 특화되어 있다. 그렇기에 많은 리소스를 필요로 한다. 보통 4GB 이상의 메모리를 요구하는데 EC2 프리티어로는 어림도 없는 메모리 용량이기에 사용하지 않았다.
Grafana + @
ELK 에 비해 소규모 프로젝트에 적합하고 매우 적은 리소스를 필요로 한다. 그리고 ELK 에 비해 스케일링이 쉽다. EC2 프리티어에서 시스템 구성이 가능했기에 이를 선택했다.
EC2 메모리 확장
먼저 모니터링 소개에 앞서, 모니터링을 어떤 서버에 구축할지 정해야 한다. 왠만하면 모니터링 서버, 개발 서버, 운영 서버 각각 분리해서 구축하는게 좋다. 하지만 나는 개발서버에 모니터링 시스템을 구축했는데 이유는 “돈” 때문이다. 개발서버로 EC2 프리티어를 사용하고 있는데, EC2 프리티어는 인스턴스에 대해 750시간을 무료로 제공한다. 즉 24시간씩 31일을 돌리면 744시간으로, 인스턴스 1개만 써도 무료시간은 대부분 다 쓰는것이다. 그래서 인스턴스 2개를 돌리면 과금이 되기때문에 기존에 있는 개발서버에 모니터링 시스템을 구축할 수 밖에 없었다.
하지만 EC2 프리티어는 1GB 메모리를 제공하는데 이는 매우 적은 용량이다. 개발서버와 모니터링 시스템을 같이 띄우면 OOM 을 마주할 것이다. 그래서 SWAP 을 이용해 메모리를 늘려야 된다. SWAP 은 디스크의 일부를 메모리 처럼 사용할 수 있게 해준다. 최대 2GB 까지 메모리로 사용할 수 있다. 당연히 디스크를 사용하기 때문에 원래 메모리 보다는 느리다. 그리고 인스턴스가 재시작될때마다 자동으로 SWAP 파일을 만들도록 설정해두면 편하다. 나는 아래 링크를 참고해 SWAP 파일을 만들었다.
내 아키텍처
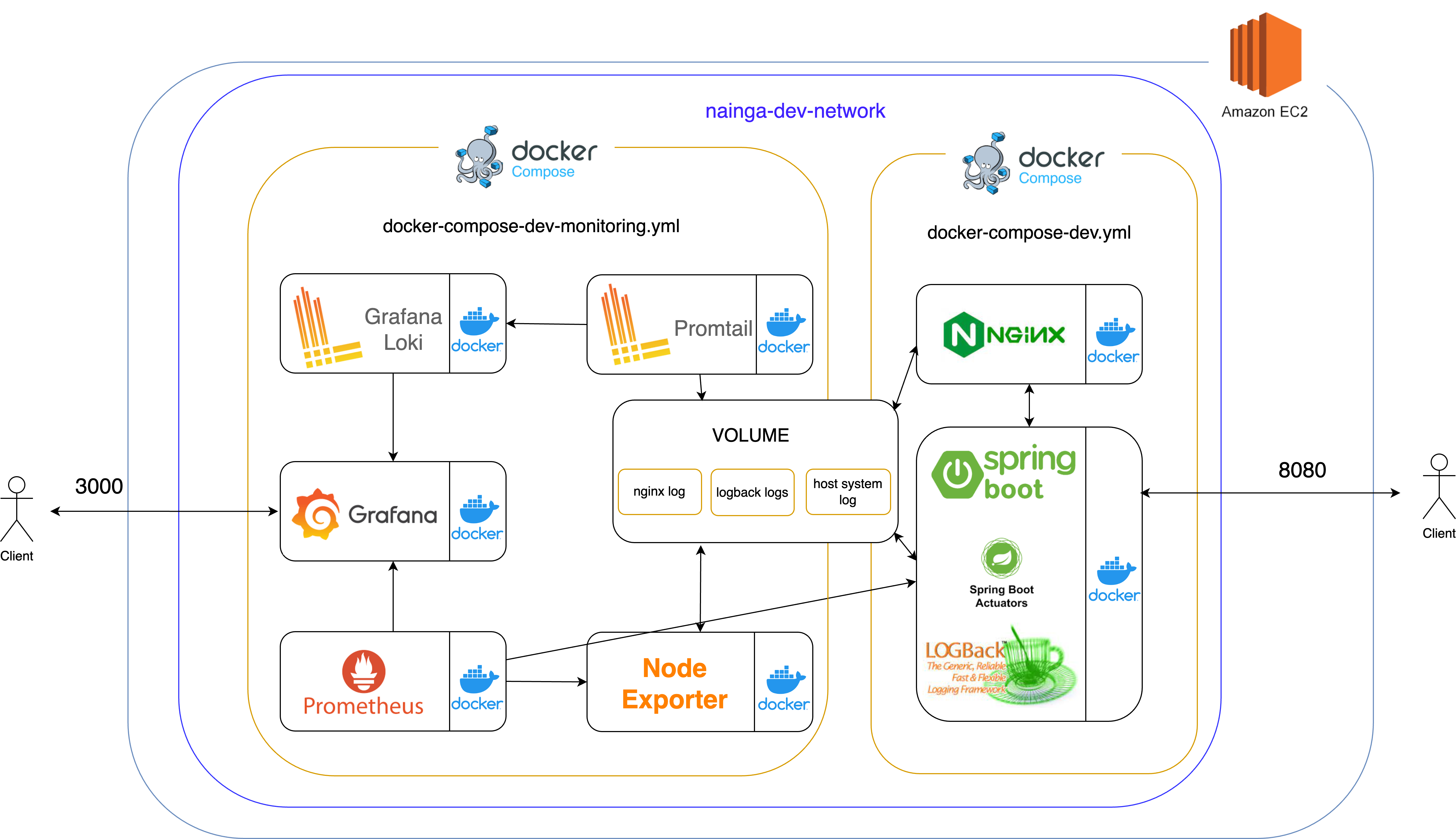
현재 내 개발서버 아키텍처는 여기 를 참고하면 된다. 그리고 아래는 내 모니터링 아키텍처 이다.
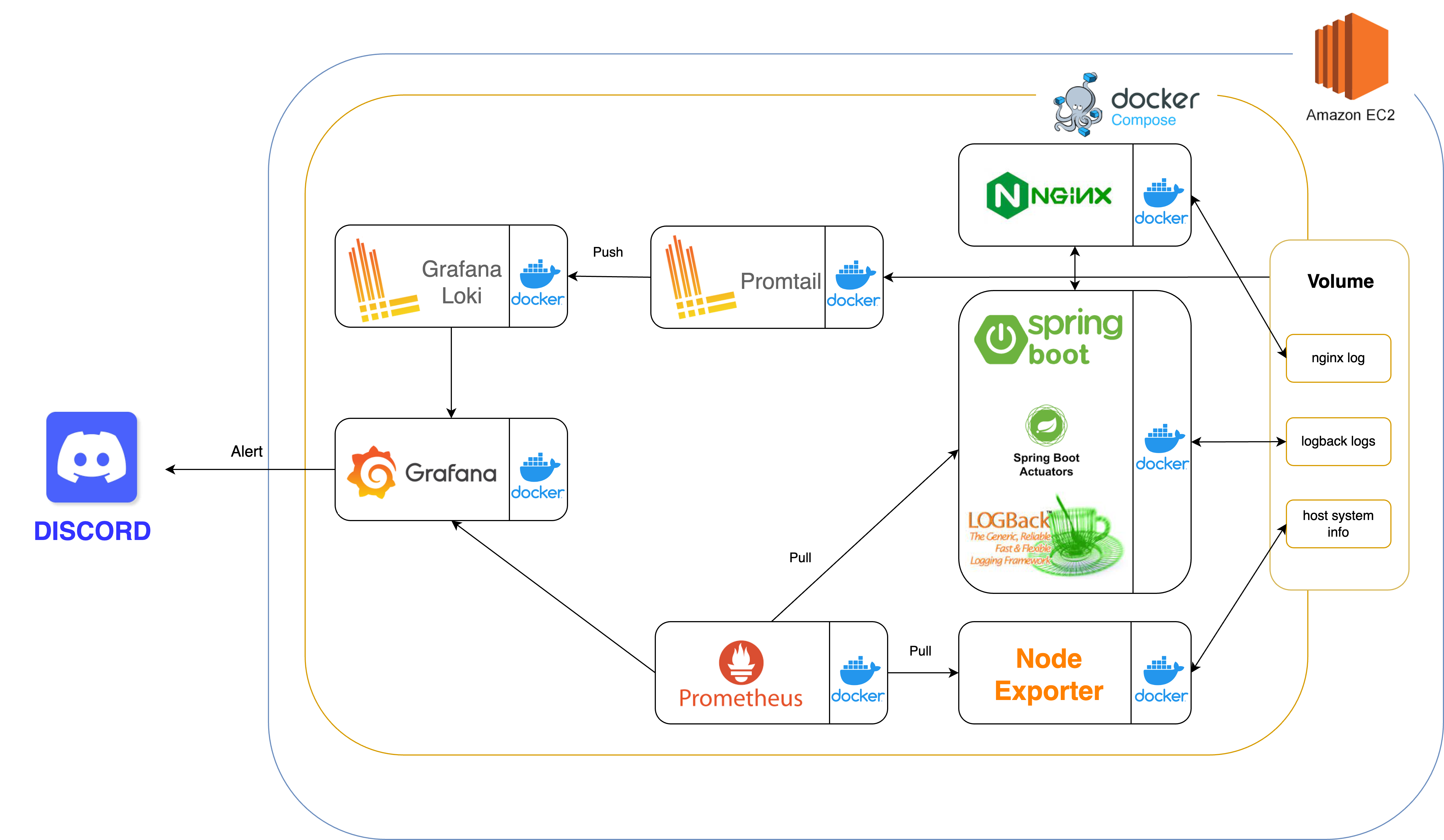
나는 모든 모니터링 툴을 Docker, Docker compose 를 이용해 구축했다. 직접 호스트에 설치해도 되지만, 나중에 Kubernetes 를 이용해 오케스트레이션을 해보고 싶어서 도커를 이용해 보았다.
아키텍처 소개는 다음과 같다. Logback 을 이용해 “파일” 로 로그를 저장해두었고 이를 호스트의 폴더에 마운트해서 볼륨에 저장해놨다.(logback logs) 참고로 Logback 을 통해 어떻게 로깅하는지는 이전글을 참고하면 된다. 마찬가지로 NGINX 에서의 로그도 호스트와 마운트해서 볼륨에 저장해두었다.(nginx log)
Volume 이란 ?
볼륨이란, 호스트와 컨테이너가 같이 쓰는 공간이라고 보면 된다. 볼륨에 있는 폴더와 파일은 컨테이너에서 수정되면 호스트에서 수정되고, 호스트에서 수정되면 컨테이너에서 수정된다. 이 처럼 실시간으로 연동되는 장소이다. 그래서 컨테이너가 종료되도 다음 컨테이너 실행때 호스트의 폴더와 연동해서 기록을 이어나갈 수 있다.
Spring Boot Actuators 는 Java Monitoring Extensions(JMX) 를 이용해 application 에 대한 정보를 수집한다. Heap memory, GC, Data connection pool 등의 메트릭 데이터를 얻을 수 있다.
Node Exporter 는 호스트의 정보를 수집한다. 호스트 컴퓨터(EC2) 의 RAM, CPU 사용률 등 메트릭 데이터를 알 수 있다. AWS 사이트에서 모니터링을 통해 확인할 수 있지만, 최종적으로 Grafana 에서 전체적으로 확인하기위해 수집한다. Node Exporter 는 Docker 보다는 서버에 직접 설치하는것을 권장한다. 그 이유는 Docker 컨테이너가 호스트와 격리할려는 특성이 호스트의 데이터 수집에 차질이 있을 수 도 있다라는 점이다. 하지만 개인적으로 Docker 를 쓰고싶었고, Docker 를 사용해서 써본 결과 딱히 문제없이 잘 돌아가서 Docker 를 이용했다.
Prometheus 는 Spring Boot Actuators, Node Exporter 로 부터 수집한 데이터를 보내달라고 요청한다.(Pull)
Promtail 은 Voulume 에 마운트되어있는, nginx log 와 logback log 에 대한 정보를 수집한다. Promtail 은 수집한 데이터를 Loki 로 보낸다. Prometheus 와 차이는 Prometheus 의 경우 시계열 데이터(float) 를 수집하고 관리하는데 특화되어 있고 Pull 요청을 통해 데이터를 수집하는 반면, Promtail 의 경우 로그 데이터(String) 를 수집하고 관리하는데 특화되어 있다.
Grafana Loki 는 Promtail 에서 받은 데이터를 Grafana 로 보낸다.
Grafana 에서는 Loki, Prometheus 를 기반으로 데이터 시각화를 해준다. Loki 와 Prometheus 는 로그 데이터를 저장해두는 DB 또는 Data source 라고 보면된다. 그래서 Grafana 는 이를 기반으로 시각화를 하고 이상 징후 발생시 Discord 로 알람을 보내게 설정했다.
간략하게 요약하면 아래와 같다.
- Logback : 백엔드 서버 로그 파일로 제공
- Nginx : Nginx 에 대한 로그 파일로 제공
- Spring Boot Actuator : application 에 대한 데이터 제공
- Node Exporter : Host System(EC2) 에 대한 데이터 제공
- Prometheus : Spring Boot Actuator, Node Exporter 에서 제공된 데이터를 Pull 해서 저장 및 관리
- Promtail : Logback, Nginx 에서 저장한 로그파일을 수집 및 Loki 서버로 Push
- Loki : Promtail 에서 Push 된 로그파일을 수집 및 관리
- Grafana : Loki, Prometheus 를 이용해 데이터 시각화 및 Discord 로 알림
데이터의 종류
모니터링으로 수집하는 데이터 종류로 로그, 메트릭, 트레이싱으로 구분된다.
- 로그 : 시스템 프로세스 개별 이벤트를 기록해둔다
- 메트릭 : 시간에 따른 변화를 나타내며 시스템 성능 및 상태(CPU 사용률, Disk 와 RAM 용량 등)를 모니터링하는데 사용되며 미리 정의된 특정 간격으로 수집된다.
- 트레이싱 : 애플리케이션에서 실행 경로를 추적하고 각 단계에서 지연, 성능 문제를 확인하기 위해 수집한다.
내 아키텍처에서 로그는 Logback, Nginx 에 해당되고, 메트릭은 Spring Boot Actuator, Node Exporter 가 해당된다.
플로우와 각 툴에 대해 간략히 소개했고 이제 실제 구현을 어떻게 하는지 알아본다.
Logback & Nginx
Logback 설정은 이전글에서 소개했고, 개발 서버 설정은 여기 를 참고하면 된다.(일부 세세한 명칭은 다를 수 있다)
Logback 은 컨테이너 내부의 app/logs 위치에 로그를 생성한다. Nginx 의 경우 컨테이너 내부에 /var/log/nginx 위치에 로그를 생성한다. Nginx 는 기본적인 로그파일로 access.log 와 error.log 를 제공한다. Logback 와 Nginx 컨테이너 내의 각각 로그 위치를 호스트 폴더에 마운트 한다.
docker-compose-dev.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
version: '3'
networks:
nainga_dev_network:
external: true
services:
server:
image: [dockerhub_id]/back:latest # 본인의 spring boot 이미지 저장소를 적으면 됩니다
container_name: server
networks:
- nainga_dev_network
ports:
- 8080:8080
environment:
- "ACTIVE_SPRING_PROFILE=dev"
volumes:
- ~/logs:/app/logs # Logback 에서 저장하는 logs 위치를 호스트에 마운트합니다.
nginx:
image: nginx:1.25-alpine
container_name: nginx
networks:
- nainga_dev_network
volumes:
- ./nginx/nginx.conf:/etc/nginx/nginx.conf
- /etc/letsencrypt:/etc/letsencrypt
- /var/lib/letsencrypt:/var/lib/letsencrypt
- ./nginx/log/nginx:/var/log/nginx # Nginx 에서 저장하는 logs 위치를 호스트에 마운트합니다.
ports:
- 80:80
- 443:443
depends_on:
- server
위와 같은 설정으로 호스트의 ~/logs 에 Logback 의 로그가 저장되고, 호스트의 ./nginx/log/nginx 위치에 Nginx 로그가 저장된다.
/app/logs ?
처음에 ~/logs:/logs 를 적었다가 제대로 마운트가 안된적이 있다. 딱히 아무런 에러도 발견되지 않아서 정확한 원인을 파악하는데 오래걸렸다. 이유는 다음과 같다.
~/logs:/logs 시에 spring boot 컨테이너(server) 내부의 /logs 폴더가 호스트의 ~/logs 에 마운트된다. 하지만 내가 spring boot 이미지를 만들때 WORKDIR app 으로 지정해두어서 컨테이너 실행시 /app 폴더에 spring boot 파일이 구성된다. 그러니 Logback 에서는 /app/logs 에 로그를 기록하고 있는데 나는 /logs 를 마운트해놨으니 호스트의 ~/logs 에는 아무것도 기록이 되지 않는것이다. (컨테이너에 내부에 /logs 폴더가 존재하지 않더라도 호스트에 ~/logs 폴더가 존재한다면 해당 폴더가 마운트되면서 에러는 발생하지 않는다.)
이렇듯 본인이 정확한 위치를 마운트하고 있는지 꼭 확인하자.
Spring Boot Actuator
Spring Boot Actuator 는 JMX, HTTP 를 이용해 Application 에 관해 다양한 데이터를 수집할 수 있다. 해당 기능을 사용하기 위해 먼저 build.gradle 에 의존성을 추가해주어야 한다.
implementation ‘org.springframework.boot:spring-boot-starter-actuator’
해당 의존성을 추가했다면 서버를 키고, http://{server}:{port}/actuator 에 접속하면 지표들이 나온다. 예를 들어 로컬에서 서버를 켰으면, http://localhost:8080/actuator 로 접속하면 된다. 현재 제공되는 지표는 기본 지표로 더 많은 정보를 얻고 싶으면 application.yml 에 아래 코드를 추가하면 된다.
1
2
3
4
5
management:
endpoints:
web:
exposure:
include: "*"
이런식으로 include: "*" 을 하고 actuator url 로 접속하면 매우 다양한 지표가 제공된다. 이렇게 많은 지표를 나는 사용하지 않으므로, 아래코드를 통해 사용할 지표인 prometheus 만 명시했다.
1
2
3
4
5
management:
endpoints:
web:
exposure:
include: "prometheus"
위의 경로로 설정하면 엔드포인트는 http://localhost:8080/actuator/prometheus 로 접속할 수 있다. 해당 URL 를 통해 필요한 메트릭을 수집할 수 있다. 하지만 이대로 서버에 띄우게 되면 보안상 문제가 생긴다. 해당 지표는 중요한 정보를 포함할 수 있는데 누구나 접속할 수 있으면 안되기 때문이다. 그래서 나만의 엔드포인트로 바꿀 필요가 있다.
1
2
3
4
5
6
7
8
9
management:
endpoints:
web:
exposure:
include: "prometheus"
# 아래 설정을 통해 :8080/actuator/prometheus 엔드포인트를 :19021/myendpoint/prometheus 로 변경
base-path: "/myendpoint"
server:
port: 19021
이렇게 설정하면 엔드포인트가 http://localhost:19021/myendpoint/prometheus 바뀐다. 이렇게 나만의 엔드포인트를 설정해서 아무도 모르게 나만 사용하도록 하자.
docker-compose-dev-monitoring.yml
나는 monitoring 을 위한 docker-compose 파일을 별도로 구성했다. 전체내용은 다음과 같고 하나씩 설명할 예정이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
version: '3'
networks:
nainga_dev_network:
external: true
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
networks:
- nainga_dev_network
# ports:
# - "9090:9090" # 도커 내부 네트워크 사용으로 인한 외부 포트 바인딩 안함
volumes:
- ./prometheus-dev.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana:latest
container_name: grafana
networks:
- nainga_dev_network
user: "$UID:$GID"
ports:
- "3000:3000"
volumes:
- ./grafana-data:/var/lib/grafana
depends_on:
- prometheus
loki:
image: grafana/loki:latest
container_name: loki
networks:
- nainga_dev_network
ports:
- "3100:3100" # 도커 내부 네트워크 사용하지만, 운영서버로 부터 데이터받기위해 열어둠
volumes:
- ./loki-dev-config.yml:/etc/loki/loki-config.yml
command: -config.file=/etc/loki/loki-config.yml
promtail:
image: grafana/promtail:latest
container_name: promtail
networks:
- nainga_dev_network
volumes:
- ~/logs:/logs
- ~/nginx/log/nginx:/nginx/logs
- ./promtail-dev-config.yml:/etc/promtail/config.yml
command: -config.file=/etc/promtail/config.yml
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
networks:
- nainga_dev_network
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
# ports:
# - 9100:9100 # 도커 내부 네트워크 사용으로 인한 외부 포트 바인딩 안함
Node Exporter
Node Exporter 는 호스트 시스템의 메트릭을 수집한다.
docker-compose-dev-monitoring.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
networks:
- nainga_dev_network
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
# ports:
# - 9100:9100 # 도커 내부 네트워크 사용으로 인한 외부 포트 바인딩 안함
EC2, GCP 인스턴스를 켜보면, 기본적으로 /proc, /sys, / 폴더가 존재한다. 해당 폴더에는 호스트의 시스템 정보가 담겨있다. 그래서 이를 마운트해서 node-exporter 가 메트릭을 수집하도록 한다. 기본적으로 node-exporter 에는 9100 포트 번호가 부여되지만, 나는 도커 내부 네트워크를 사용하기에 외부로 열어두지 않았다. 이에 대한 자세한 설명은 나중에 설명하겠다. 앞으로도 내부 네트워크에 대해 자주 언급되므로 먼저 보고싶다면 여기 를 먼저 읽어도 된다.
Prometheus
Prometheus 에서는 Spring Boot Actuators, Node Exporter 에서 수집한 메트릭들을 달라고 Pull 요청을 한다. 그러면 해당 메트릭을 받아 저장하고 관리한다.
docker-compose-dev-monitoring.yml
1
2
3
4
5
6
7
8
9
prometheus:
image: prom/prometheus:latest
container_name: prometheus
networks:
- nainga_dev_network
# ports:
# - "9090:9090" # 도커 내부 네트워크 사용으로 인한 외부 포트 바인딩 안함
volumes:
- ./prometheus-dev.yml:/etc/prometheus/prometheus.yml
prometheus 에서 설정파일인 prometheus-dev.yml 은 아래와 같다.
prometheus-dev.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# metrics_path : metric 경로 지정
# scrape_interval : 수집 주기
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'nainga-dev'
metrics_path: 'myendpoint/prometheus'
static_configs:
- targets: ['server:19021']
- job_name: 'node-dev'
metrics_path: '/metrics'
static_configs:
- targets: ['node-exporter:9100']
수집주기
1
2
3
global:
scrape_interval: 15s
evaluation_interval: 15s
여기서 scrape_interval 은 메트릭 지표 수집 주기다. 15초 마다 pull 요청을 보내서 메트릭 지표를 수집한다. evaluation_interval 은 규칙을 평가하고 이에 따라 알람을 발생시키는 주기이다. 현재 15초마다 평가를 실시하지만, 나는 Grafana 를 통해 알람기능을 사용하므로 여기서 설정을 안해주어도 상관없다.
Pull
1
2
3
4
5
scrape_configs:
- job_name: 'nainga-dev'
metrics_path: 'myendpoint/prometheus'
static_configs:
- targets: ['server:19021']
해당 과정은 Prometeus 가 어디에 Pull 요청을 해서 메트릭을 수집할지 적는 코드다. 위 코드는 Spring boot actuator 에 대한 메트릭 지표를 수집한다.
job_name: 이름 설정으로 다른job_name과 중복된 이름만 아니게 잘 설정해주면 된다.metrics_path: 경로를 지정하면 된다. 이전에 Spring boot actuator 에서 myendpoint/prometheus 로 설정 했기에 이를 적어주었다.targets: 경로를 지정해준다. ip:port 로 적어도 되지만, 나는 docker 내부 네트워크를 사용하므로 docker 서비스명으로 연결이 가능하다.(server 는 docker-compose-dev.yml 에서 설정한 spring boot 서비스명이다.)
마찬가지로 node-exporter 도 설정해주면 된다.
Promtail
Promtail 은 Logback 과 Nginx 에서 생성한 로그를 수집하고 Loki 서버로 보낸다. Loki 서버로 보내는 이유는 Promtail 로그를 관리하는 기능없고 단순히 수집만 가능하기에 이를 관리해줄 Loki 서버로 보내야한다. Promtail 의 구체적인 로그 수집 과정은 다음과 같다.
- Springboot 컨테이너에서 Logback 이 로그를 파일로 저장한다. 마찬가지로 Nginx 컨테이너에서 log 를 파일로 저장한다.
- 1번과정에서 컨테이너에 저장된 로그들을, 호스트와 동기화 해서 호스트에도 로그를 저장한다.
- Promtail 은 호스트에 있는 로그를, Promtail 컨테이너 내부에 저장한다.
- Promtail 컨테이너 내부에 저장된 로그를 주기적으로 Loki 서버에 보낸다.
docker-compose-dev-monitoring.yml
1
2
3
4
5
6
7
8
9
10
promtail:
image: grafana/promtail:latest
container_name: promtail
networks:
- nainga_dev_network
volumes:
- ~/logs:/logs
- ~/nginx/log/nginx:/nginx/logs
- ./promtail-dev-config.yml:/etc/promtail/config.yml
command: -config.file=/etc/promtail/config.yml
promtail 를 띄울때, Logback 이용해 호스트에 마운트한 ~/logs 폴더와 Nginx 가 호스트에 마운트한 ~/nginx/log/nginx 폴더를 원하는 promtail 경로에 마운트해준다. promtail 설정 파일은 아래와 같다.
promtail-dev-config.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml # 동기화 작업을 이루기 위해 promtail이 읽은 마지막 로그 정보를 저장하는 곳
clients:
- url: http://loki:3100/loki/api/v1/push # push할 Loki의 주소(내부 컨테이너를 이용하므로 ip 대신 docker-compose-dev-monitoring 서비스 이름으로 지정)
scrape_configs:
- job_name: debug
static_configs:
- targets:
- localhost
labels:
job: debug_logs
__path__: ./logs/debug/*.log # debug 폴더 내에 log 파일들 모두 수집
- job_name: info
static_configs:
- targets:
- localhost
labels:
job: info_logs
__path__: ./logs/info/*.log # info 폴더 내에 log 파일들 모두 수집
- job_name: warn
static_configs:
- targets:
- localhost
labels:
job: warn_logs
__path__: ./logs/warn/*.log # warn 폴더 내에 log 파일들 모두 수집
- job_name: error
static_configs:
- targets:
- localhost
labels:
job: error_logs
__path__: ./logs/error/*.log # error 폴더 내에 log 파일들 모두 수집
- job_name: nginx
static_configs:
- targets:
- localhost
labels:
job: nginx_log
__path__: ./nginx/logs/*.log
Push
1
2
clients:
- url: http://loki:3100/loki/api/v1/push
해당 url 은 수집된 로그를 push할 Loki의 주소를 적는다. 나는 내부 컨테이너를 사용하므로 docker-compose-dev-monitoring.yml 에서 정의된 loki 의 서비스명을 적어주었다. 이것도 마찬가지로 ip:port 로 적어줄 수 있다. 예를 들어 호스트인 EC2 ip 주소가 11.22.33.44 라면 http://11.22.33.44:3100/loki/api/v1/push 를 적어주면 된다.
수집
1
2
3
4
5
6
7
8
scrape_configs:
- job_name: nginx
static_configs:
- targets:
- localhost
labels:
job: nginx_log
__path__: ./nginx/logs/*.log
해당 과정은 타겟을 대상으로 로그를 수집하는 과정이다. targets 는 promtail 이 설치된 경로를 의미한다. 컨테이너에 내부에 설치했으니, 보통 localhost 를 적어주면 된다. __path__ 에는 promtail 컨테이너안에 로그가 저장되어 있는 위치를 적어주면 된다. promtail 를 띄울때 ~/nginx/log/nginx:/nginx/logs 로 마운트했기 때문에, nginx 로그는 컨테이너의 /nginx/logs 에 저장된다. 헷갈리지 않게 주의하자.
Loki
Promtail 에서 수집한 로그를 받아서 관리한다.
docker-compose-dev-monitoring.yml
1
2
3
4
5
6
7
8
loki:
image: grafana/loki:latest
container_name: loki
networks:
- nainga_dev_network
volumes:
- ./loki-dev-config.yml:/etc/loki/loki-config.yml
command: -config.file=/etc/loki/loki-config.yml
로키서버는 기본 포트로 3100 을 제공하지만, 도커 내부 네트워크를 사용하므로 열어두지 않았다.
loki-dev-config.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
auth_enabled: false
server:
http_listen_port: 3100
common:
instance_addr: 127.0.0.1
path_prefix: /loki
storage:
filesystem:
chunks_directory: /loki/chunks
rules_directory: /loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v12
index:
prefix: index_
period: 24h
ruler:
alertmanager_url: http://localhost:9093
해당 Loki 서버 설정은 딱히 건드린게 없다. Loki github 에서 Docker 를 사용할때 기본설정은 그대로 들고온 것이다.
혹시 Promtail 버전과 Loki 버전이 다른가?
Promtail 과 Loki 는 한 몸이라고 보면 된다. 그렇기에 같은 버전을 사용해주어야 한다. 여기서는 :latest 를 사용해 최신버전을 가져오도록 했는데, Promtail 과 Loki 는 항상 같이 최신버전을 업데이트하므로 괜찮다. 만약 수동으로 다른 버전을 각각 적용했다면 연동이 안 될 수 있다.
Grafana
Grafana 는 Loki 와 Prometheus 에 수집한 데이터들을 기반으로 시각화하는 기능을 제공한다.
docker-compose-dev-monitoring.yml
1
2
3
4
5
6
7
8
9
10
11
12
grafana:
image: grafana/grafana:latest
container_name: grafana
networks:
- nainga_dev_network
user: "$UID:$GID"
ports:
- "3000:3000"
volumes:
- ./grafana-data:/var/lib/grafana
depends_on:
- prometheus
그라파나도 도커로 띄워 사용한다. 여기서 중요한 점은 ./grafana-data:/var/lib/grafana 를 통해 볼륨을 꼭 설정해주어야 한다. 왜냐하면 그라파나에 접속해서 대시보드를 구성하고 할텐데 해당 설정이 호스트에 저장되지 않으면 grafana 컨테이너가 종료될때마다 구성했던 대시보드가 다 날라갈것이다. 그리고 user: "$UID:$GID" 를 설정해주어야 그라파나 컨테이너 내부의 /var/lib/grafana 에 쓰기 권한을 가진다. 이에 대한 이슈는 여기 에서 확인할 수 있다.
Grafana 의 기본 포트는 3000 이다. Grafana 는 외부에서 접속할것이기 때문에 포트번호를 열어두어야 한다.
Grafana 접속
Node-Exporter, Promtail, Loki, Prometheus, Grafana 를 도커로 띄웠다면 Grafana 를 접속해보자. http://{호스트 주소}:3000 으로 접속할 수 있다.

접속하면 위와같이 Grafana 로그인 화면이 나온다. Email or username : admin, Password : admin 을 적으면 로그인이 된다. 이는 기본 id, pwd 로 로그인한뒤 변경해주도록 하자. 로그인을 했다면 Connections > Data sources 로 들어가 Add new data source 버튼을 클릭해 prometheus 와 loki 를 추개해줘야 한다. 아래는 추가해준 화면이다.

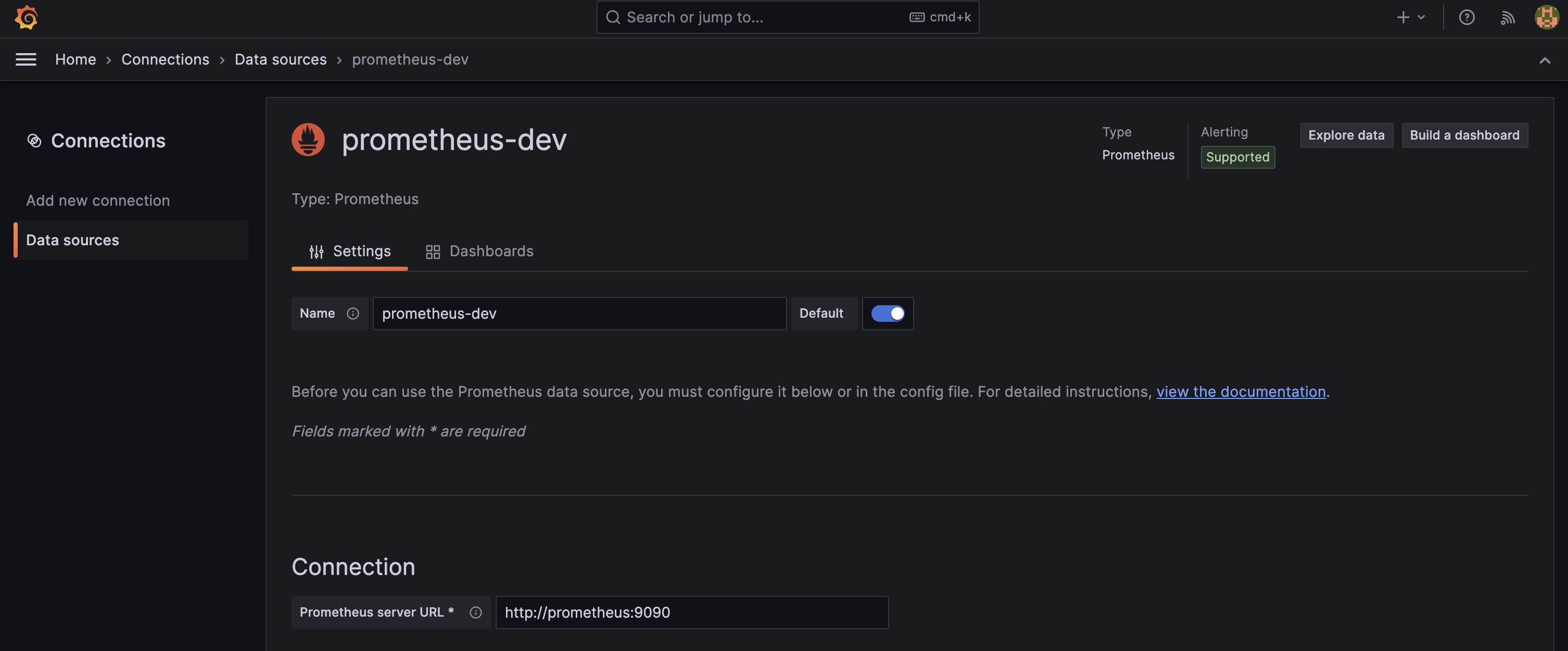
아래는 prometheus 를 추가하는 과정이다. connection 에 http://prometheus:9090 을 적어주면 EC2 에 도커로 띄워져있는 prometheus 와 연동 된다. 여기서도 prometheus 는 docker-compose-dev-monitoring.yml 에 구성되어있는 서비스 이름이다. 당연히 prometheus 대신 ip 를 적어줘도 된다.
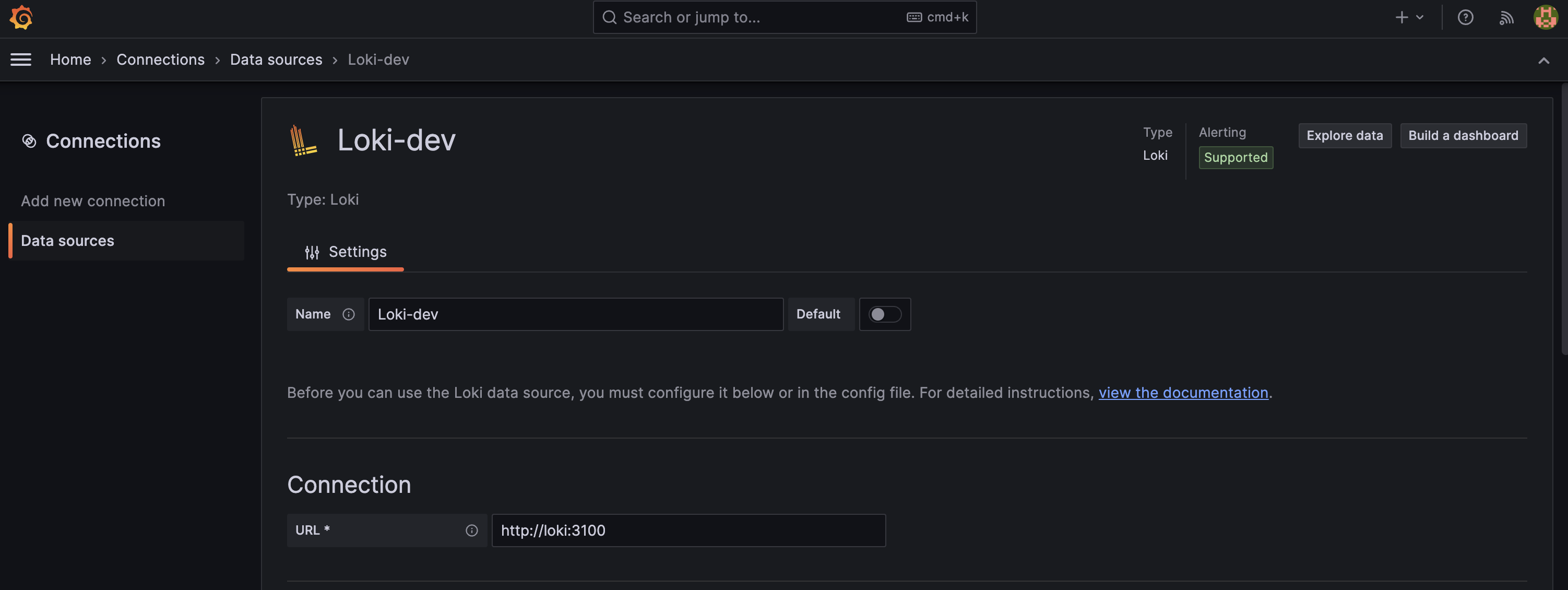
아래는 loki 를 추가하는 과정이다. 마찬가지로 connection 에 http://loki:3100 을 적어주면 된다.
혹시 Grafana 가 접속이 안된다고요??
Grafana 는 외부에서 호스트 주소와 3000포트를 이용해 접속한다. 당연히 호스트의 보안그룹에 해당 포트를 열어둬야 접속이 가능하다. EC2 를 사용중이니 EC2 보안그룹으로 이동해 3000 포트를 열어주도록 하자.
대시보드 구성
이제 Data source 는 연동했으니 이를 시각화 해줄 대시보드를 구성해보자.
Spring boot actuator 메트릭을 시각화
Dashboards > New > Import 로 들어가 ID 를 19004 를 입력하자. 여기서 ID 는 Grafana Labs 에서 다른 사람이 만들어두었던 대시보드를 그대로 가져오는 것이다. 내가 직접 구성하면 한세월일테니 오픈소스를 빌리자..!
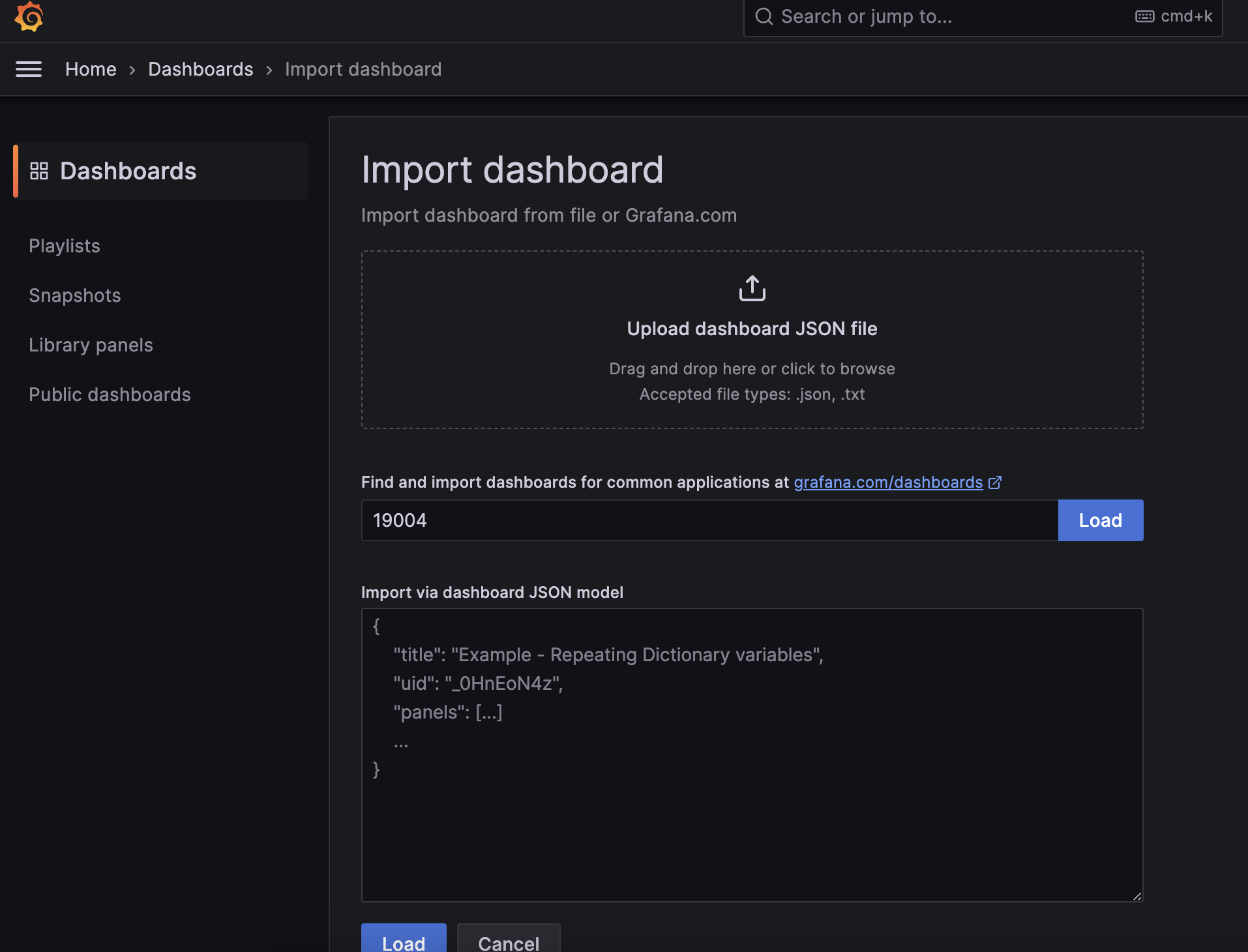
ID 를 입력하고 Load 버튼을 클릭하면 아래 화면이 나온다. 여기서 원하는 Name 을 설정하고, 이전에 Data source 로 등록해두었던 Prometheus 를 연동하면 된다.

결과적으로 아래와같이 시각화를 할 수 있다! 뭔가 전문적인 느낌이 난다.
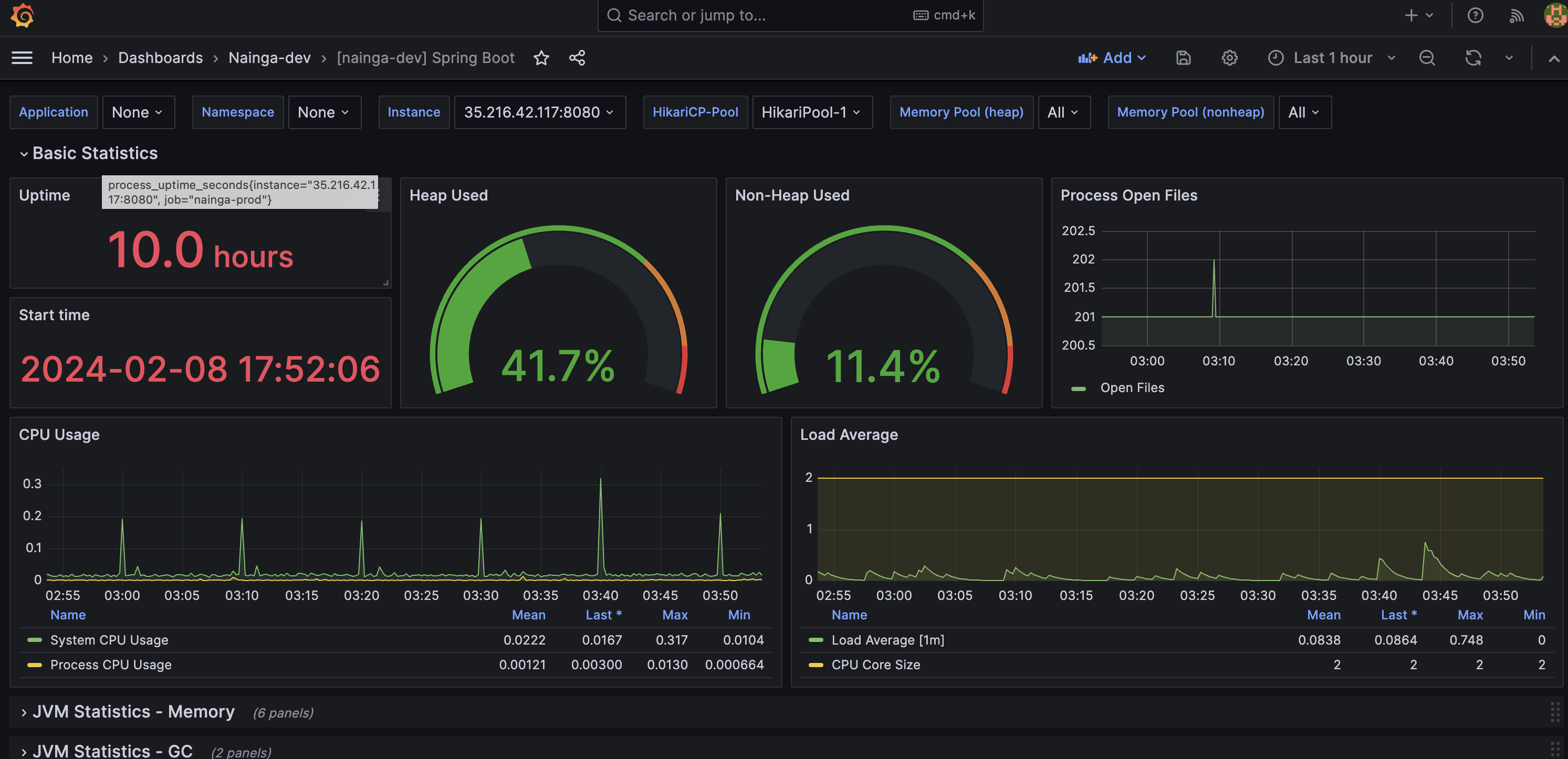
Host System 메트릭을 시각화
Host System 도 마찬가지로 Dashboards > New > Import 로 들어가 ID 를 1860 으로 로드하고, Name 을 설정한뒤 Prometheus 를 연동하면 된다. 알아서 Prometheus 에서 node-exporter 를 찾아서 시각화 해줄것이다. 시각화 화면은 아래와 같다.
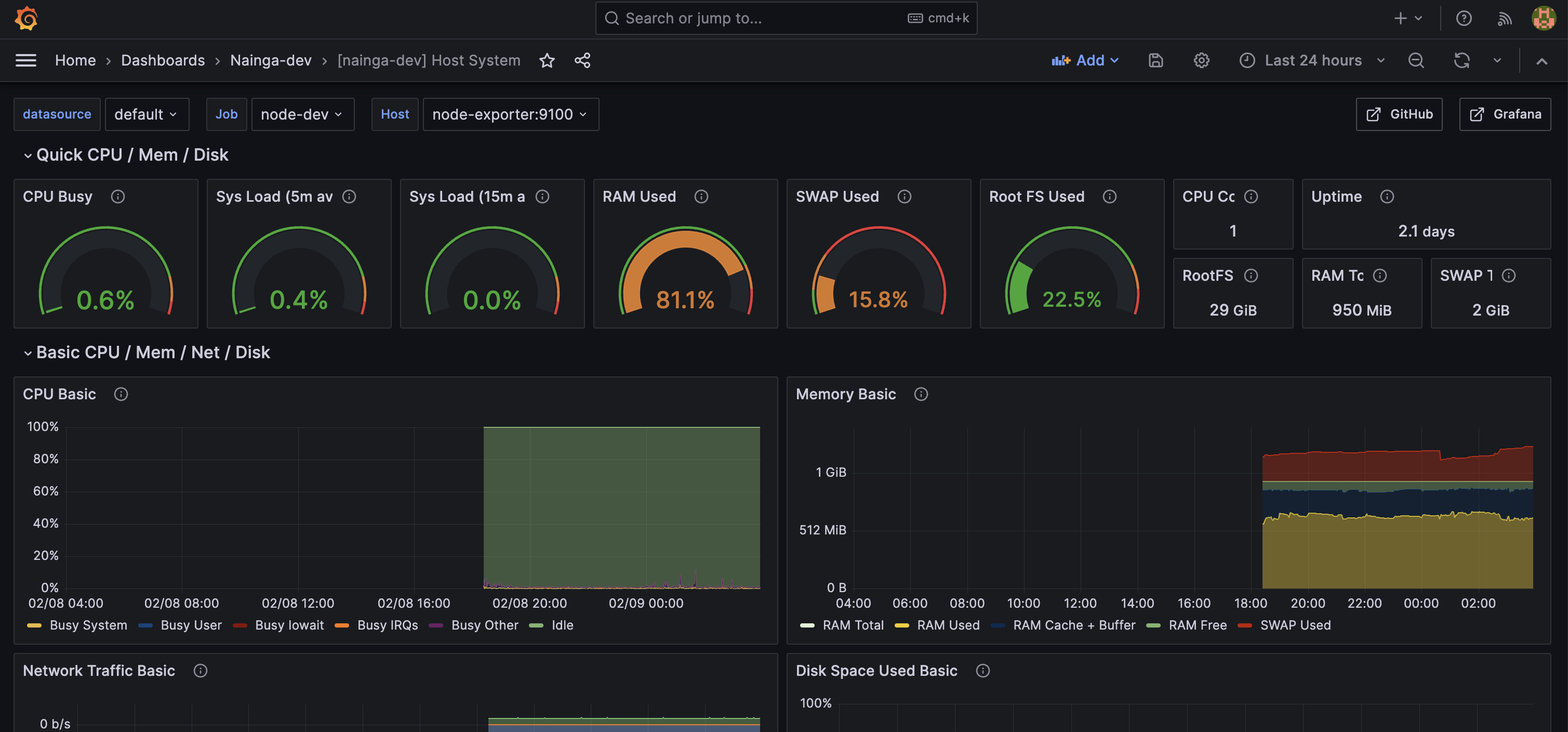
Logback & Nginx 로그 시각화
로그는 대시보드를 따로 못찾아서 직접 구성했다. Dashboards > New > New Dashboard > + Add visualization 을 통해 직접 보드를 만들 수 있다. 여기서 data source 를 Loki 로 고르면 된다.

그 다음 Label filters 에서 job = debug_logs 식으로 원하는 로그를 선택하고 Run query 버튼을 클릭해보자. 그리고 Open visualization suggestions 를 클릭하고 Logs 시각화화면을 클릭하자.
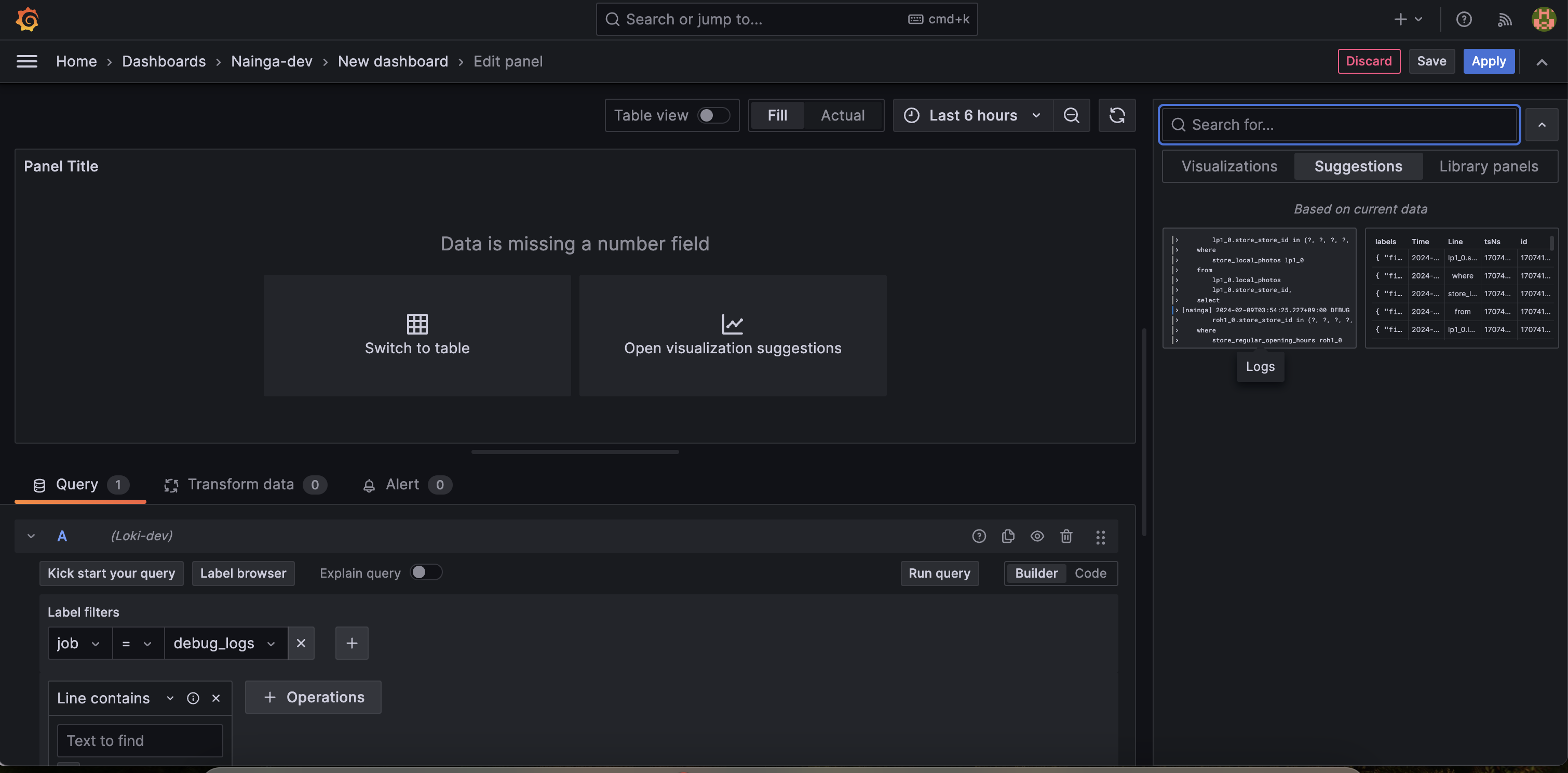
그러면 아래와 같이 화면이 보여지고 우측 상단에 Apply 버튼 클릭해 적용시킬 수 있다.
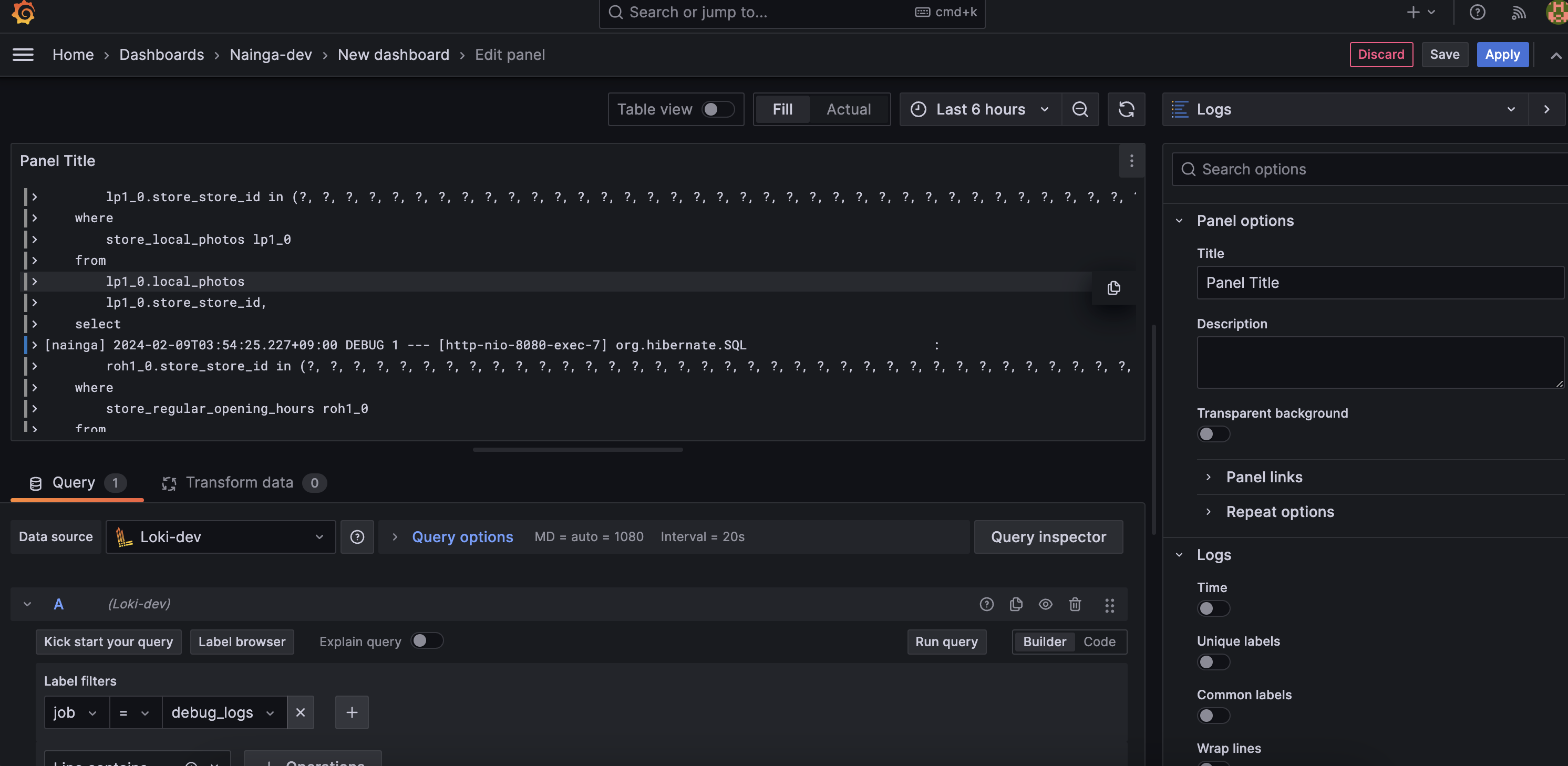
이런식으로 필요한 로그 수 만큼 반복하여 최종적으로 아래와 같은 대시보드를 구성했다. 한눈에 Nginx Log, ERROR, WARN, INFO, DEBUG 로그를 확인할 수 있다.

Label filter 에 로그가 안뜰때?
Label filter 에서 job 을 누르고 로그를 선택할 때 없는 로그가 있을 수 있다. 보통 error_logs 가 없을 수 있는데, 이는 error_logs 에 아무것도 기록되지 않아 용량이 0 일 때 나타나는 현상이다. 아무것도 기록되어 있지 않으면 Grafana 에서 뜨지 않는다.
한 눈에 보고 싶은데
Spring boot actuator, Host System, Logback & Nginx 대시보드들을 한 화면에서 보고싶은데 방법이 없을까? 고민했었다. 서로 다른 대시보드를 합치는 기능은 따로 보이지 않았다. 그래서 방법을 찾다가 코드를 직접합치기로 했다. Grafana 대시보드는 시각화되서 정보를 보여주지만, 당연히 이것도 코드로 짜여져 있다. 실제로는 아래 이미지 처럼 JSON Model 로 구성되어 있었다.

그래서 각각의 대시보드의 JSON Model 를 분석해서, 필요한 내용을 짜집기해서 통합 대시보드를 만드는데 성공했었다.

시각화 내용이 많아서 스샷 하나에 다 담지 못하는게 아쉽지만… 이렇게 한 페이지에서 전부 확인이 가능하다.
Discord 로 알림보내기
Grafana 는 알림 기능을 지원한다. Alerting > Contact points 에서 + Add contact point 버튼을 클릭해 알림봇을 만들자.
적절한 이름을 설정하고 Discord Webhook URL 을 설정해주자. Discord Webhook URL 을 얻는 방법은 여기에서 포스팅 했었다.
그 다음 Alerting > Alert rules 에서 원하는 알람을 추가해주면 된다. 그러면 조건을 만족하면 Discord 로 알람이 간다. 나는 CPU 사용률이 일정이상 넘어가면 알림이 가도록 했다. 실제로 EC2 에서 CPU 사용률이 70% 이상이 되었을 때 서버가 죽을때가 많았다.
도커 내부 네트워크
도커 네트워크 아키텍처는 아래와 같다.
도커 내부 네트워크를 이용하면, port 를 열어두지 않아도 서비스명으로 접근이 가능하다. 만약 도커 내부 네트워크를 사용하지 않는다면 호스트 주소와 포트를 이용해 접근해야 한다. 예를 들어 호스트 주소가 11.22.33.44 이라면, Node Exporter 에 접근하기위해 11.22.33.44:9100 으로 접근한다. 이는 외부에서 누구나 해당 주소로 접근이 가능하다. 보안상 취약해진다는 뜻이다. Node Exporter, Promtail, Prometheus 에 누구나 접속이 가능하면 누구나 로그와 메트릭을 볼 수 있게 되고 이는 보안상 굉장히 취약해진다.
하지만 도커 내부 네트워크를 사용하면, Node-Exporter 를 띄울때 포트번호를 오픈하지 않아도 서비스명으로 접근이 된다. 같은 도커 네트워크 안에 구성되어 있다면, node-exporter:9100 으로 접근이 된다. 당연히 포트를 오픈하지 않았기에 외부에서 11.22.33.44:9100 이나 node-exporter:9100 으로 접근이 불가능하다. 외부로 공개가 불필요한것은 공개하지 않게해주는게 보안상 좋다.
그렇지만 포트를 오픈해야 하는것도 있다. Grafana 의 경우 3000 포트를 열어놔서 외부에서 접근할 수 있도록 했다. 누구나 접근이 가능하지만, 아이디와 비밀번호를 모르면 이용할 수 없기에 보안성을 지킬 수 있다. 또 Spring Boot Actuator 의 경우 누구나 11.22.33.44:8080/actuator/prometheus 로 접근해서 메트릭지표를 볼 수 있지만, 별도의 설정을 통해 나만의 엔드포인트를 구성해서(11.22.33.44:19021/myendpoint/prometheus) 아무나 모르는 장소가 되어 보안성을 지킬 수 있다. 외부로 공개되는 시스템의 경우 최소한의 보안성을 생각해두자.
도커 내부 네트워크 생성
아래 커맨드를 입력하면 현재 도커 네트워크를 알 수 있다.
docker network ls
그리고 아래 커맨드를 사용해 나만의 네트워크를 만들 수 있다.
docker network create nainga_dev_network
위와 같이 입력하면 “nainga_dev_network” 라는 이름의 네트워크가 생성된다. 기본으로 네트워크 드라이버가 bridge 로 구성되고, 이를 사용하면 된다.
현재 docker-compose-dev.yml 와 docker-compose-dev-monitoring.yml 로 두 개의 docker-compose 파일로 구성되어 있다. 다른 파일로 구성되어 있지만 같은 네트워크를 사용하기 위해 두 파일 에는 아래 코드를 넣어준다.
1
2
3
networks:
nainga_dev_network:
external: true
위 코드는 nainga_dev_network 가 현재 호스트에 존재한다고 인식한다. 그 다음 아래코드를 도커 서비스마다 넣어주면 같은 네트워크로 구성이 된다.
1
2
networks:
- nainga_dev_network
다른 파일로 구성되도 같은 네트워크를 사용하면 서로 서비스명을 이용해 접근이 가능해진다. 만약 같은 네트워크를 사용하지 않는다면 당연히 서로 접근이 불가능하고 같은 파일내에서만 접근이 된다.
마무리
개발서버는 리소스가 부족하다보니 가끔식 죽을때가 있다. 이전에는 죽어도 내가 수동으로 확인하지 않으면 언제 죽었는지 몰라 대응이 늦었다. 이에 대해 알람을 통해 즉각적으로 대처하고, 시각화 모니터링을 통해 원인을 바로 파악해서 개발서버가 다운되었을때 금방 복구가 가능했다. 다음 글에서는 운영서버 모니터링에 대해 적어볼려고 한다.
Reference
Node Exporter 설치하기
Spring Boot Actuator, Prometeus 모니터링
Promtail, Loki 를 이용한 모니터링
Docker 내부 네트워크 사용
모니터링 아키텍처 종류